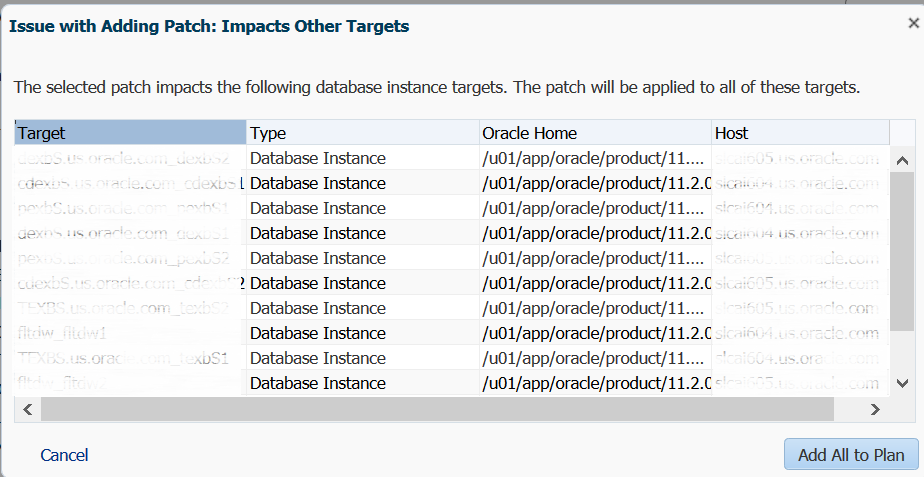
So, there is a lot to cover on this topic and I hope Part I got you ready for more! Part II, I’m going to cover the following areas of the AWR Warehouse:
- Installation
- Access
- ETL Load Process
Installation
Let’s start with Prerequisites:
- The AWR Warehouse Repository must be version 11.2.0.4 or higher.
- The Targets and I think this will get a few folks, need to be 12.1.0.2 or higher, (now folks know why some docs aren’t available yet!:))
- Just as with installing ASH Analytics, etc., make sure your preferred credentials are set up for the database you plan to use for the AWR Warehouse repository.
- You should already have your database you plan on using for the AWR Warehouse repository discovered in your EM12c console.
- Any database targets you wish to add at the this time to the AWR Warehouse setup should also be pre-discovered.
- For a RAC target or AWR Warehouse, ensure you’ve set up a shared location for the ETL load files.
Now the repository is going to require enough space to receive anywhere from 4-10M per day in data, (on average…) and Oracle highly recommends that you don’t run anything else on the AWR Warehouse database, so don’t use your current EM12c repository database or your RMAN catalog, etc… Create a new repository database to do this work and manage the data.
To Install:
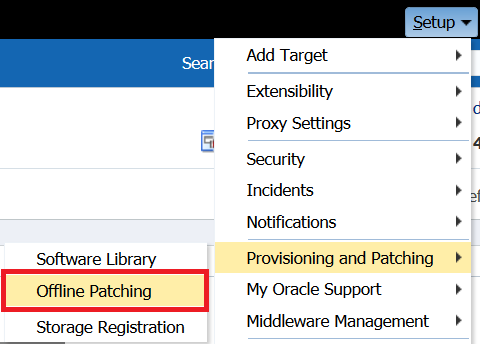
Click on Targets, Databases, which will take you to your list of databases. Click on the Performance drop down and choose AWR Warehouse. As no AWR Warehouse has been set up, it will take you promptly to the wizard to proceed with an initial workflow page.
Click on the Configure option and choose the database from your list of available databases to make your AWR Warehouse repository database. Notice that you next need to select Preferred Credentials for both the database target and the host it resides on. As the ETL process does perform host agent host commands, both these credentials are necessary.
Next page you’ll set up the retention period for your AWR Warehouse. You can set the value to number of years or choose to retain the data indefinitely for you data hoaders… ![]() You can then set the interval to upload data, (how often it processes the ETL load…) which defaults at 24hrs, but you can set it as often as once per hour. Due to potential server load issues considering size of environment, # of targets, etc., I would recommend using the default.
You can then set the interval to upload data, (how often it processes the ETL load…) which defaults at 24hrs, but you can set it as often as once per hour. Due to potential server load issues considering size of environment, # of targets, etc., I would recommend using the default.
Next set up the location for the ETL dump files. For RAC, this is where you will need to specify the shared location, otherwise, for non-RAC environments, the agent state directory will be default. I recommend setting up an exclusive directory for RAC and non-RAC targets/AWR Warehouse.
Click on Submit and monitor the progress of the deployment in the EM Job Activity. The job will be found quickly if you search for CAW_LOAD_SETUP_*.
Accessing the AWR Warehouse
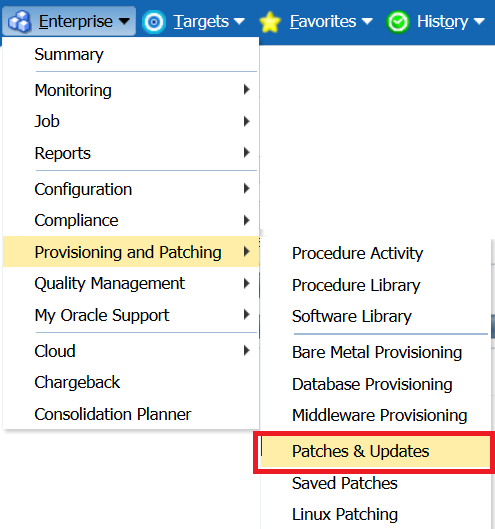
Once set up, the AWR home can be accessed from the Targets menu, click on Databases, then once you’ve entered the Databases home, (databases should be listed or shown in a load map for this screen, click on Performance and AWR Warehouse.
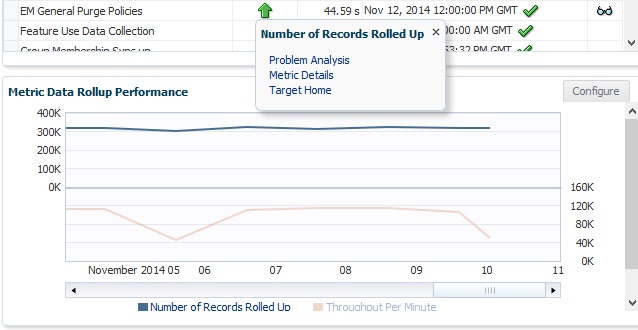
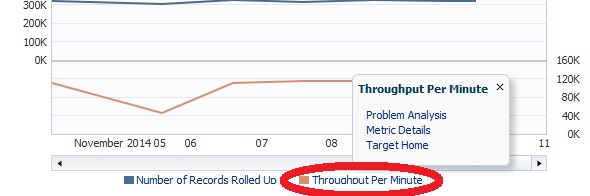
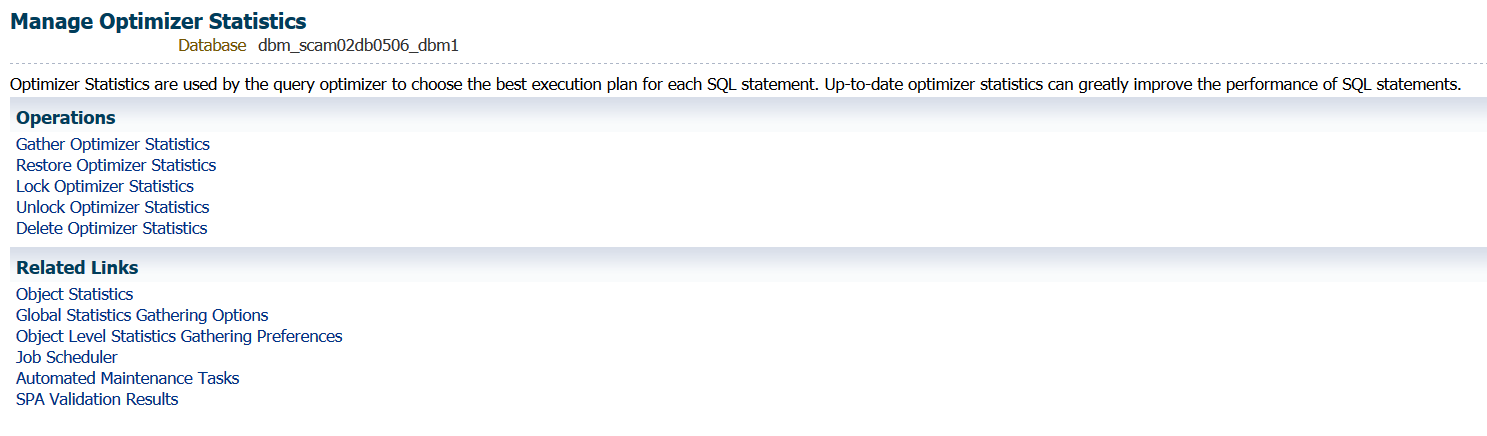
The following dashboard will then appear:
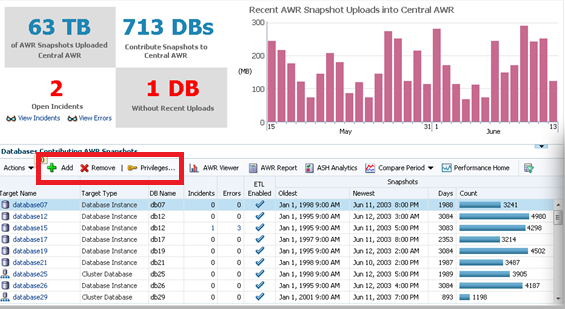
From this dashboard you can add or remove source targets and grant privileges to administrators to view the data in the AWR Warehouse.
You can also view the AWR data, run AWR reports, do ADDM Comparisons, ASH Analytics and even go to the Performance home for the source target highlighted in the list.
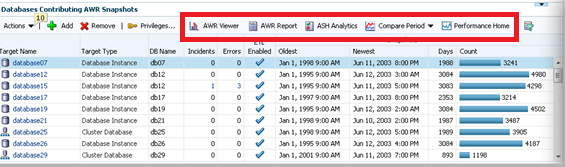
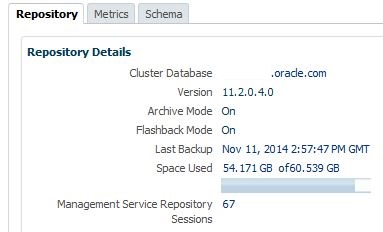
Note for each of the databases, you can easily see the Source target name, type, DB Name, (if not unique…) # of Incidents and Errors. You can see if the ETL load is currently enabled, the dates of the newest and oldest snapshots in the AWR Warehouse and the # of AWR snapshots that have been uploaded to the repository.
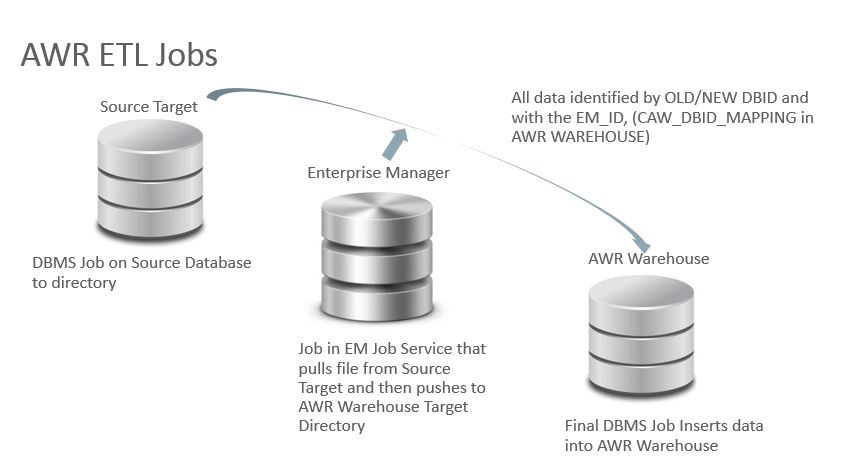
Now how does this all load in?
The AWR Warehouse ETL
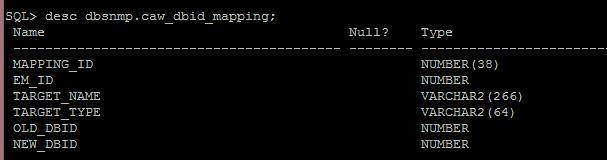
The process is actually very interesting. Keep in mind. These are targets, source and destination, but what will drive the ETL job? How will the job be run on the targets and then to the destination AWR warehouse? Now I was sure the repository used TARGET_GUID to keep everything in order, but since the ETL does have to push this data from a source target through to the destination repository via the host, there is definite use of the DBID, too.
To upload the AWR snapshots from the target to the AWR warehouse, an extract is added with a DBMS job as part of a new collection on a regular interval. There is first a check to verify the snapshot hasn’t been added to the warehouse repeatedly and then the extract is identified by DBID to ensure unique info is extracted.
The second step in the ETL process is the EM12c step. Now we are onto the EM Job Service and it submits an EM Job on the host to transfer the data from the target to the warehouse host for the third part of the ETL process. This is an agent to agent host process to transfer the dump files directly from target host to AWR warehouse host, so at no time do these dump files end up on the EM12c host unless you were housing your warehouse on the same server as your EM12c environment.
The last step for the ETL process is to then complete the load to the AWR warehouse. This is another DBMS job that takes the dump files and imports them into the AWR Warehouse schema. DBID’s are mapped and any duplicates are handled, (not loaded to the final warehouse objects…)The ETL is able to handle multi-tenant data and at no time is there a concern then if more than one database has the same name.
Retention Period
Once the retention period has been reached for any AWR warehouse data, the data is purged via a separate job set up in EM12c at the time of creation, edited later on or set with the EM CLI command. A unique setting can be made for one source target from another in the AWR Warehouse, too. So let’s say, you only want to keep three months of one database, but 2 years of another, that is an option.
For Part III, I’ll start digging into more specifics and features of the AWR Warehouse, but that’s all for now!

 Tags:
Tags:
Del.icio.us
|
Facebook |
TweetThis |
Digg
|
StumbleUpon
|

Copyright © DBA Kevlar [AWR Warehouse in EM12c, Rel 4, Part II], All Right Reserved. 2014.